Catherine Taylor to present at SCA 2019, ISMAR 2019 & SIGGRAPH 2019
News
CDE Research Engineer Catherine Taylor will be presenting at no less than three prestigious international conferences this year.
The IEEE ISMAR is the leading international academic conference in the fields of Augmented Reality and Mixed Reality. The ACM SIGGRAPH / Eurographics Symposium on Computer Animation (SCA) has been the premier forum for innovations in the software and technology of computer animation since 2002. SIGGRAPH 2019 is the world’s leading annual interdisciplinary educational experience for inspiring transformative advancements across the disciplines of computer graphics and interactive techniques.
Details of Catherine’s papers are below:
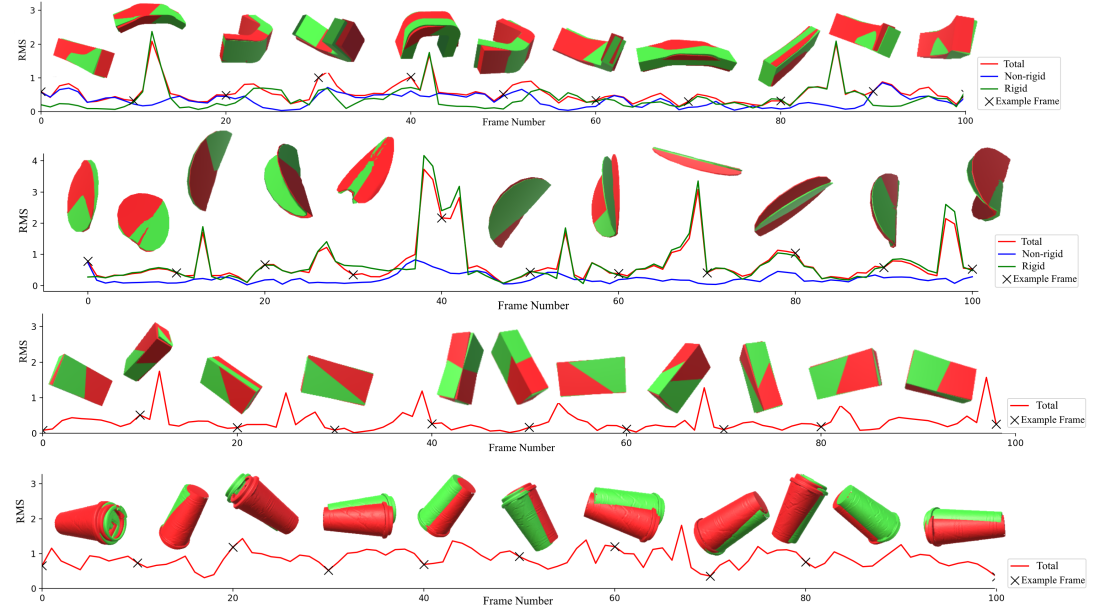
1. “VR Props: An End-to-End Pipeline for Transporting Real Objects into Virtual and Augmented Environments“, Catherine Taylor, Chris Mullany, Robin McNicholas, Darren Cosker, Full paper at International Symposium on Mixed and Augmented Reality (ISMAR) 2019, Beijing
Improvements in both software and hardware, as well as an increase in consumer suitable equipment, have resulted in great advances in the fields of virtual and augmented reality. Typically, systems use controllers or hand gestures to interact with virtual objects. However, these motions are often unnatural and diminish the immersion of the experience. Moreover, these approaches offer limited tactile feedback. There does not currently exist a platform to bring an arbitrary physical object into the virtual world without additional peripherals or the use of expensive motion capture systems. Such a system could be used for immersive experiences within the entertainment industry as well as being applied to VR or AR training experiences, in the fields of health and engineering. We propose an end-to-end pipeline for creating an interactive virtual prop from rigid and non-rigid physical objects. This includes a novel method for tracking the deformations of rigid and non-rigid objects at interactive rates using a single RGBD camera. We scan our physical object and process the point cloud to produce a triangular mesh. A range of possible deformations can be obtained by using a finite element method simulation and these are reduced to a low dimensional basis using principal component analysis. Machine learning approaches, in particular neural networks, have become key tools in computer vision and have been used on a range of tasks. Moreover, there has been an increased trend in training networks on synthetic data. To this end, we use a convolutional neural network, trained on synthetic data, to track the movement and potential deformations of an object in unlabelled RGB images from a single RGBD camera. We demonstrate our results for several objects with different sizes and appearances.
2. “Transporting Real Objects into Virtual and Augmented Environments“, Catherine Taylor, Murray Evans and Darren Cosker – Sketches Paper at Symposium of Computer Animation (SCa) 2019, LA
Despite the growing interest in virtual and augmented reality (VR/AR), there are only a small number of limited approaches to transport a physical object into a virtual environment to be used within a VR or AR experience. An external sensor can be attached to an object to capture the 3D position and orientation but offers no information about the non-rigid behaviour of the object. On the other hand, sparse markers can be tracked to drive a rigged model. However, this approach is sensitive to changes in positions and occlusions and often involves costly non-standard hardware. To address these limitations, we propose an end-to-end pipeline for creating interactive virtual props from real-world physical objects. Within this pipeline we explore two methods for tracking our physical objects. The first is a multi-camera RGB system which tracks the 3D centroids of the coloured parts of an object, then uses a feed-forward neural network to infer deformations from these centroids. We also propose a single RGBD camera approach using VRProp-Net, a custom convolutional neural network, designed for tracking rigid and non-rigid objects in unlabelled RGB images. We find both approaches to have advantages and disadvantages. While frame-rates are similar, the multi-view system offers a larger tracking volume. On the other hand, the single camera approach is more portable, does not require calibration and more accurately predicts the deformation parameters.
3. “VRProp-Net: Real-time Interaction with Virtual Props“, Catherine Taylor, Robin McNicholas, Darren Cosker – poster at Siggraph 2019, LA
Virtual and Augmented Reality (VR and AR) are two fast growing mediums, not only in the entertainment industry but also in health, education and engineering. A good VR or AR application seamlessly merges the real and virtual world, making the user feels fully immersed. Traditionally, a computer-generated object can be interacted with using controllers or hand gestures [HTC 2019; Microsoft 2019; Oculus 2019]. However, these motions can feel unnatural and do not accurately represent the motion of interacting with a real object. On the other hand, a physical object can be used to control the motion of a virtual object. At present, this can be done by tracking purely rigid motion using an external sensor [HTC 2019]. Alternatively, a sparse number of markers can be tracked, for example using a motion capture system, and the positions of these used to drive the motion of an underlying non-rigid model. However, this approach is sensitive to changes in marker position and occlusions and often involves costly non-standard hardware [Vicon 2019]. In addition, these approaches often require a virtual model to be manually sculpted and rigged which can be a time consuming process. Neural networks have been shown to be successful tools in computer vision, with several key methods using networks for tracking rigid and non-rigid motion in RGB images [Andrychowicz et al. 2018; Kanazawa et al. 2018; Pumarola et al. 2018]. While these methods show potential, they are limited to using multiple RGB cameras or large, costly amounts of labelled training data.












